
Retrieval-Augmented Generation (RAG) has become the go-to pattern for grounding LLM responses with real data. But as RAG systems scale, retrieving context on the fly can become expensive and make an AI app or system sluggish. Storing common and static information in a cache (i.e., a fast, easily accessible storage layer for frequently used data) can go a long way toward reducing latency and costs for your AI project.
The RAG Performance Problem
Traditional RAG follows this pattern for each query:
- The user submits a prompt, e.g., vacation ideas for a trip to NYC.
- The system converts that prompt into a set of numerical values called a ‘vector’ (using an embedding model).
- The vector database performs an approximate nearest neighbor (ANN) search to return the top k most similar chunks.
- The system scores and sorts the retrieved chunks based on relevance to the query using cosine similarity (a measure of how close two vectors point in the same direction), a reranker model (a smaller language model trained to look at the question and each chunk and score how well they match), or heuristics (e.g., favoring chunks with titles or recent publish dates).
- The system retrieves the most relevant chunks of content (e.g., sections of documents).
- The system injects those chunks into the prompt that is sent to an LLM (like folding cheese into your enchilada sauce).
- The LLM generates a response based on the original question and the retrieved context.
RAG is a pretty well-oiled machine and a popular option for AI app developers. However, all that intelligence comes at a cost.

Caching can help you put your RAG ambitions on a budget.
How Caching Helps
Instead of retrieving context for every query, we can identify common prompts that are typically satisfied with relatively static content and cache their context. Since I’m a visual processor, I think of caching like creating an HOV lane on a highway for frequent questions with predictable answers. Let the queries that need fresh context battle it out in the other lanes.
Queries that may benefit from caching include anything you may find on an FAQ page or a page that doesn’t require frequent updates, e.g., your business hours and contact information, return policy, SaaS product pricing tiers, onboarding checklists, etc.
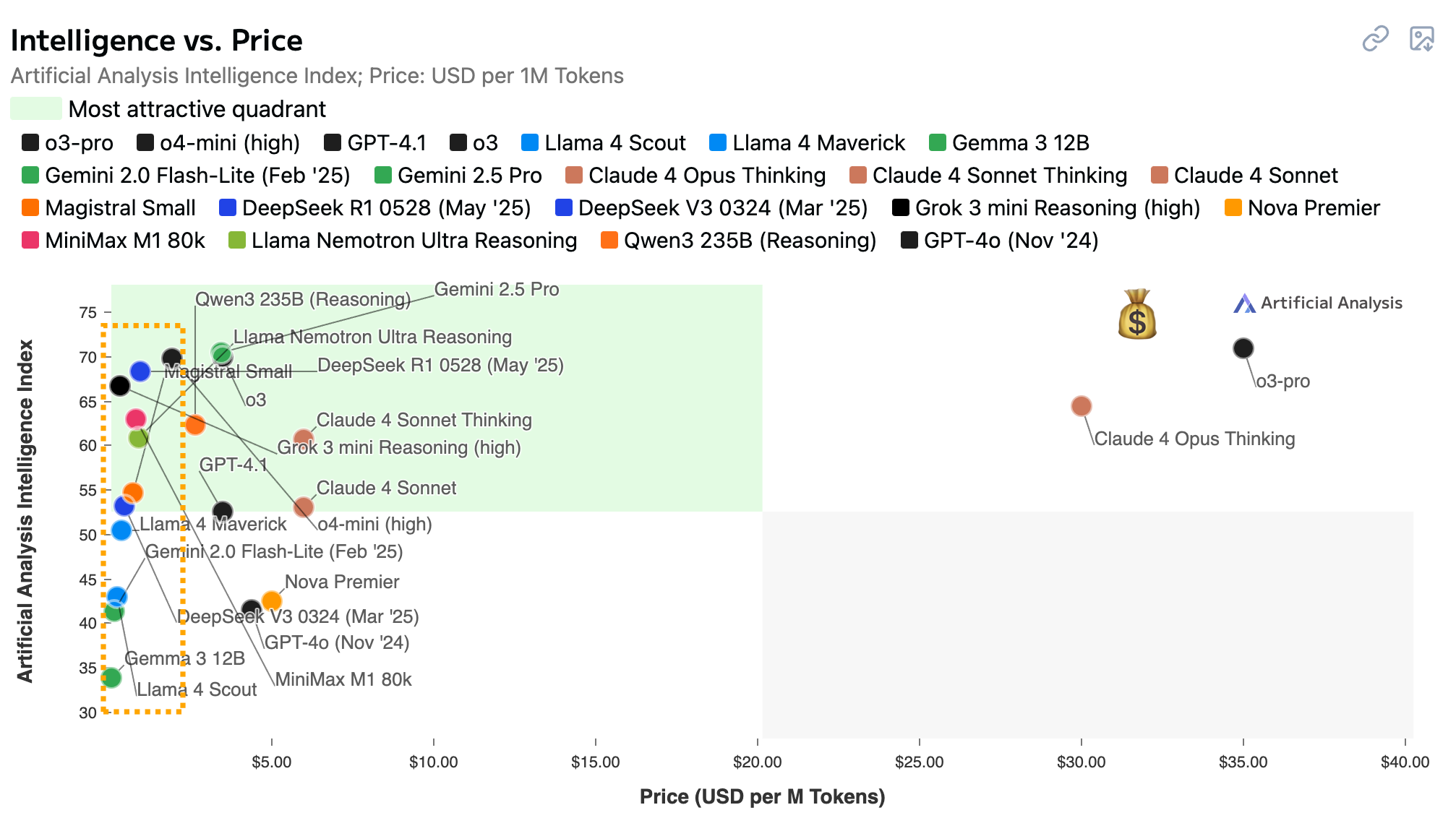
So let’s say a user asks about your company’s return policy. You could use a router (more on that in a minute) to recognize this information is cached, retrieve the cached information, and send it to the LLM along with the user’s prompt. Since you basically just need the LLM to synthesize a response rather than provide the information, you can even trim costs by using a less expensive model that performs well in chat. My AI Strategy App has you covered in this discovery process, but the Artificial Analysis leaderboard is a great jumping-off point that will help you target models that excel in quality and price for chat tasks. You do not need a huge, Einstein-smart model to stitch together responses. The models in the highlighted section hugging the y-axis are, in most cases, more than sufficient for this task.
You can save even more on inference costs by running a locally stored open-source model—or even fine-tuning it with examples from your documents or chat transcripts that reflect your company’s tone and voice. In some cases, this can cost as little as $50 (based on a true story).
Using a cache eliminates the need to generate embeddings or query a vector database. Instead, you can rely on lightweight pattern matching. For more flexibility, you can scaffold your search with a touch of natural language processing (NLP). I often incorporate stemming (which reduces words to their root forms) and lemmatization (which maps words to their dictionary forms based on context) in the search features I build into my apps.
Implementation Guide
Step 1: Identify Cacheable Patterns
If you don’t know which topics are cacheable, you can use machine learning (ML) to help you cluster topics from your query logs. You can start by using a sentence transformer model to bulk convert your queries into vector embeddings (e.g., SBERT or multi-qa-MiniLM-L6-cos-v1). These numerical representations let you find questions that are semantically similar even when worded differently. You can then use cosine similarity to measure how similar queries are to each other.
The diagram above shows how this works: Each query is passed through a BERT-based model to generate a contextual embedding, then a pooling operation reduces the output into a single sentence embedding. These embeddings are what you’ll use to compare semantic similarity between queries using techniques like cosine similarity.
Queries with high cosine similarity (typically >0.8) are asking essentially the same thing. These similarity scores can then be applied to clustering algorithms (e.g., K-means or DBSCAN) to group related queries together. I provide guidance for picking a clustering model in my Machine Learning Model Picker tool. (I’ve pre-filtered it for clustering.)
Once your prompts aggregated into labeled clusters, you’ll then want to analyze which ones appear most frequently and represent stable topics (like policies, procedures, or product specs). These are the clusters that are your best caching candidates. This ML-driven approach scales to millions of queries and catches semantic similarities that simple keyword matching would miss.
Step 2: Build Your Cache Strategy
For each cacheable topic cluster, you’ll want to preload the relevant context that your RAG system would normally retrieve. This means pulling the actual text chunks from your knowledge base ahead of time and structuring them for quick access.
To make your strategy scalable, I recommend baking flexibility into your cache entries to handle different aspects of each topic. For example, a return policy cache could include pre-loaded sections about international returns, exceptions, and common edge cases with its core policy. If you store these as ready-to-use context strings, that’s more context that could be passed to your LLM.
I built my AI Strategy App and ML Model Picker from the ground up using structured data (as opposed to a database, like I did with my AI Timeline). As I was deciding on features and approaches, I realized how many different ways I could approach the organization of these tools and, hence, the structure of my markup. That also applies in this context (bad pun intended). One approach may be something like this:
# Example cache structure
cache = {
"return_policy": {
"context": {
"main": "Our return policy allows returns within 30 days...",
"international": "For international orders, returns must be...",
"exceptions": "Final sale items and opened software cannot..."
},
"patterns": ["return", "refund", "exchange", "money back"],
"last_updated": "2024-01-15",
"ttl_days": 7
},
"business_hours": {
"context": {
"main": "We're open Monday-Friday 9AM-5PM EST..."
},
"patterns": ["hours", "open", "closed", "when available"],
"last_updated": "2024-01-15",
"ttl_days": 30
}
}
Note: ‘ttl_days’ stands for ‘time to live in days’. It establishes how long the cached content should be considered valid before it needs to be refreshed. For example, policy documents might need monthly refreshes while technical specs remain stable for entire quarters. When the TTL expires, you’d re-fetch the latest content from your knowledge base to ensure the cache stays current. This prevents serving outdated information while avoiding unnecessary updates for stable content. It’s a common caching pattern borrowed from web development.
Step 3: Implement Smart Routing
At the heart of your enhanced RAG system is a smart router that decides whether to use cached content or perform a full retrieval. This router acts as a traffic controller, analyzing incoming queries and making split-second decisions about the most efficient path to an answer.
If you’re the AI strategist aiding engineers in fleshing out your app’s routing strategy, one thing they might find helpful is to map query features with routing direction. This could be as simple as a bulleted list that looks something like this:
Cache:
- Short, direct questions (often indicate FAQ-style queries)
- High keyword overlap with your cached topics
- Questions about static information (policies, procedures, specifications)
- Responses with high confidence scores in prior model outputs
- Responses that don’t tend to have follow-up questions
RAG:
- References to specific dates, times, or recent events
- Long, detailed questions with unique context
- Queries mentioning specific user data or personalized information
- Questions with low similarity to any cached patterns
- High variance in retrieved chunks for semantically similar queries (i.e., similar questions retrieve different documents)
Step 4: Monitor and Adapt
Your caching system should evolve based on real usage patterns. Setting up comprehensive monitoring helps you understand what’s working and what needs adjustment. The data you gather will naturally guide your decisions about which content to cache and when to refresh it. Since you can’t improve what you don’t measure, here’s some guidance on a few metrics to consider tracking.
Cache Hit Rate
Cache hit rate tells you what percentage of queries successfully use cached content. A healthy system might see 40-70% hit rates, though this varies widely. Breaking this down by topic can surface interesting patterns. For example, you might find your return policy cache serves 500 queries daily while your shipping rates cache barely gets touched.
Response Accuracy
Response accuracy requires a more nuanced approach to measurement. One may be to implement a sampling system where you periodically compare cached responses against fresh RAG retrievals. If certain cached topics start producing outdated or incomplete answers, you can use that feedback loop to augment your cache input or structure.
Query Latency
Query latency tells the performance story. Cached queries should be dramatically faster, often 5-10x. When measuring latency, percentiles give you a better picture than averages. The p50 (median) shows your typical user experience, p95 shows what 95% of users experience, and p99 captures those worst-case scenarios. If your p50 cached response is 200ms but your p99 is 5 seconds, that may require further investigation.
Followup Prompt Frequency
User satisfaction often comes through indirect signals. For example, a spike in follow-up questions might indicate your cached answers may be incomplete. To measure this, you can track conversation flows by logging whether users ask additional questions within the same session after receiving a cached response.
So let’s say someone asks “What’s your return policy?” and receives a cached response but then immediately follows with “Can I return without a receipt?” or “Days to make a return.” You may decide those fast follows are acceptable, and the system working as designed. Or it could suggest your cached responses are incomplete.
If this is something you want to monitor, you could track query sequences for both RAG-generated and cached responses. If you find that a disproportionate percentage of your cached responses trigger follow-up questions compared to RAG responses, your cache may need more comprehensive coverage.
For example, in LangSmith’s trace view, you might see:
Session_123:
1. User: "What's your return policy?" → [cached_response] → 200ms
2. User: "But what if I don't have a receipt?" → [follow_up] → 150ms
3. User: "What about opened items?" → [follow_up] → 180msLangSmith lets you filter sessions where cached responses were followed by multiple queries in quick succession. You can even set up custom evaluators to automatically flag these patterns. The platform shows you the full conversation context, making it easy to spot when users aren’t getting complete answers from your cache.
Other tools with similar conversation tracking features include Arize AI (which has a ‘Conversations’ view) and even basic session replay tools like FullStory or LogRocket, if you’re building a web interface. The key is having something that groups related queries into sessions rather than treating each query as isolated.
Monitoring Tools
The right monitoring setup depends on your scale and existing infrastructure. Many teams start with free tools and upgrade as their needs grow. The key is choosing something you’ll actually use rather than the most feature-rich option. Here are a few worth considering:
Free/Open Source:
- Grafana + Prometheus: Full observability stack for tracking custom metrics
- LangSmith (free tier): Built specifically for LLM applications, tracks chains and latencies
- Weights & Biases (free tier): Good for ML experiment tracking and monitoring
- CloudWatch (AWS free tier): Basic metrics if you’re already on AWS
- RAGAS: Open source framework for evaluating RAG performance
- Custom logging: Sometimes a simple Python logger writing to files is enough to start (what I use for my apps)
Paid:
- LangSmith (paid tiers): Advanced features for production LLM monitoring (my fave paid tool)
- Arize AI: Purpose-built for ML/LLM observability
- DataDog: Comprehensive monitoring tool with LLM-specific integrations
- New Relic: Strong real-time monitoring and alerting capabilities
- Honeycomb: Excellent for debugging complex query pattern
- WhyLabs: Focuses on ML monitoring and drift detection
The tool you choose matters less than actually implementing monitoring. Start with whatever fits your existing stack. Even basic logging can reveal valuable patterns that guide your caching strategy.
Final Thoughts
RAG doesn’t have to be slow or expensive. By adding intelligent caching, you can build systems that are both powerful and efficient. Start simple, measure everything, and scale what works. Your users (and budget) will thank you.
Leave a Reply