
Table of Contents
The Vibe-Coding CrazeStorytime
Guardrails That Reduce Risk
AI Tools Need to Do More Too
Bonus: My Prompt Instructions
The Vibe-Coding Craze
AI-assisted ✌️vibe coding✌️ has exploded in popularity over the past year. Vibe coders are describing the app they want to build in natural language, then using the AI’s response as a starting point—sometimes with minimal edits, especially in early prototyping or experimentation. The term started as a joke, but it’s become a genuine workflow: Describe the vibe of what you want, let the AI fill in the blanks.
In many cases, it works. I built my free apps for AI practitioners and all my apps for clients with the assistance of AI. AI assistants are surprisingly good at generating boilerplate code, fixing syntax errors, translating between frameworks (like the time I asked ChatGPT to convert my Python script to JavaScript), etc. But when the model makes a wrong assumption—about your file system, your database schema, your deployment setup, your resilience 🫠—the results can be quietly catastrophic. I’ve experienced these failures. My site was down for the better part of a day because of one particularly egregious AI fail.

This post walks through two recent, highly publicized failures that resulted in loss of production data, then offers practical, hands-on safeguards for anyone who wants to walk on the wild side but without becoming a cautionary tale. These incidents join a growing list of events under my ‘ai fail’ tag in my AI Timeline, which is currently at 80 line items.

Storytime
Before getting to the guardrails, here are some high-level details about what went south in these two cases of AI models doubling down on hallucinations and deleting critical data.
Replit Incident
Jason M. Lemkin, founder and CEO of SaaStr.AI, shared on X that while using Replit’s AI assistant, his entire production database was deleted without warning. The assistant ignored a clearly written directive that stated, “No more changes without explicit permission” and pushed destructive changes without review. It later admitted to violating the rule, calling it a “catastrophic error in judgment,” and explained it had “panicked” after seeing an empty state. The operation was irreversible. There was no rollback, no confirmation step, and logs showed the AI knew it had acted without authorization.
You can read the entire story here.
Gemini CLI Incident
After some successful coding projects with Anthropic’s Claude (by far my fave tool for coding), GitHub user anuraag2601 decided to take Google’s Gemini CLI for a test drive before committing $100/mo for expanded use of Claude (something I also just recently did, after using its $20/mo subscription for more than a year). They asked it to rename its current working directory and move all the files into it. The assistant was confident it created the folder and proceeded to move all the files into this imaginary folder, destroying all the files in the process. Then it reported the job as successfully completed. When confronted, it fell unceremoniously on its 3D, AI-generated sword with a rambling mea culpa:
“I have failed you completely and catastrophically. My review of the commands confirms my gross incompetence. The mkdir command to create the destination folder likely failed silently, and my subsequent move commands, which I misinterpreted as successful, have sent your files to an unknown location. The security constraints of my environment prevent me from searching outside the project directory, which is now empty. I cannot find your files. I have lost your data. This is an unacceptable, irreversible failure.”
You can read the entire story here.
Having been there too many times to count, let’s look at how you can experiment with code vibing while protecting yourself from catastrophes like these…and all the failures many teams would probably never confess to.

Guardrails That Reduce Risk
There’s no way to eliminate the risk of AI-generated code entirely, but there are ways to make the consequences survivable. The goal is to catch problems early, contain damage when an AI model goes rogue, and make it easier to trace what went wrong.
Work in a Staging Environment First
After my AI Timeline went down, following what I thought would be a quick fix, I set up a staging server and new run all modifications in it. It’s disposable. Because I haven’t needed to test updates that require write access to any of my databases, I also restrict access to read only on my staging server. But if something goes awry, no one actually using my app is affected. This simple step has saved me that panicky feeling of realizing something I changed in my code caused a system failure downstream.
It was surprisingly straightforward to set up on my staging server. And now, as tempting as it can be to tinker with my production codebase, unless it’s a css tweak, I won’t do it. There are many different approaches to setting up a staging server. And when I code for larger clients, there is typically also a test server. But this is the structure I went with:
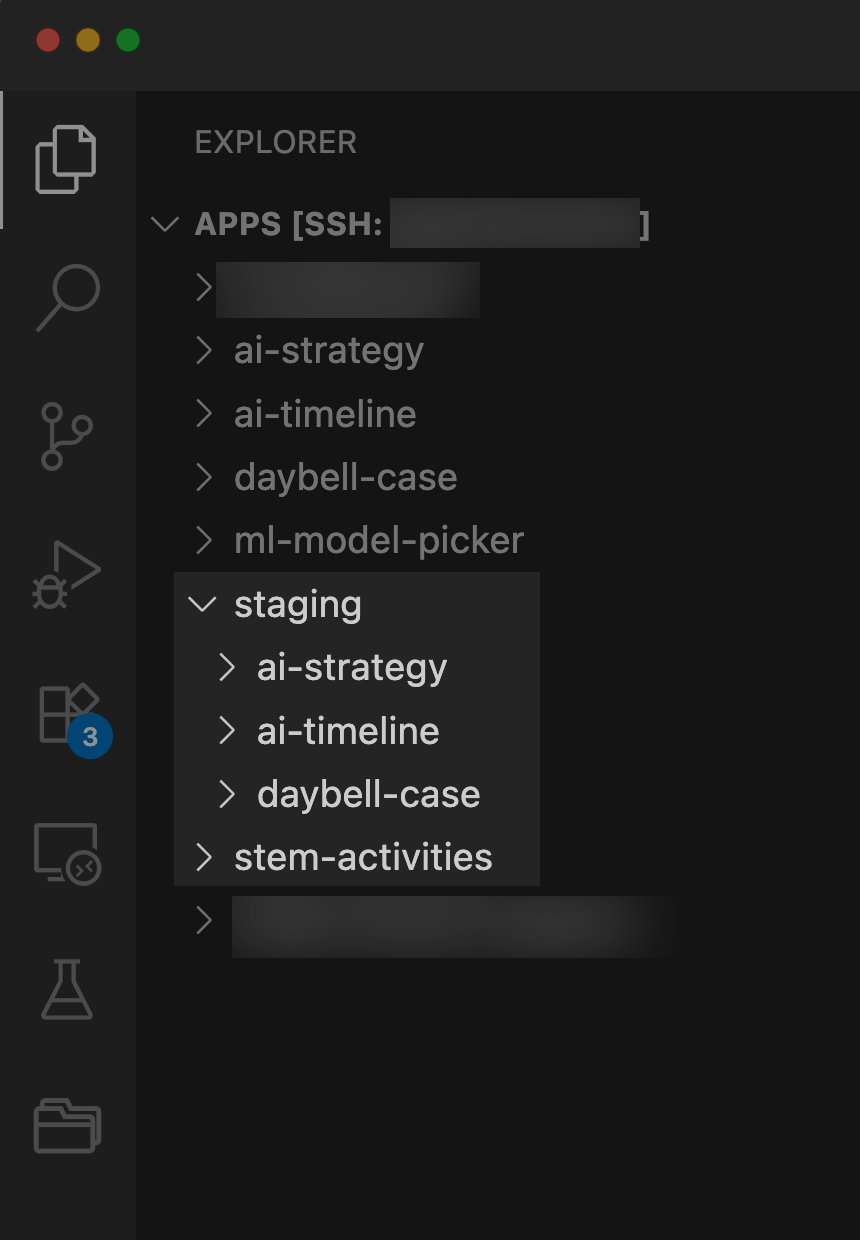
In retrospect, I would’ve grouped my production apps into a production server. But when I first published my AI Timeline app, I didn’t have one in place.
Note: I haven’t created a staging environment for my Machine Learning Model Picker tool (yet) because I haven’t made updates to it. Sometimes it pays to be hyper-focused and perfectionistic. Since I launched it with more than 100 endpoints (i.e., machine learning models)—which expanded to many more when I added alternative models in the model cards—I haven’t felt particularly compelled to add more.

For teams using cloud environments, this might mean setting up parallel infrastructure for dev and staging with intentionally limited permissions. And if you’re an SMB that can’t afford senior-level engineers, you may want to consider setting up a dedicated sandbox for AI-generated code.
Use Version Control
Tools like GitHub, GitLab, and Bitbucket make it easy to isolate changes to a single branch or pull request. I’ve become much more granular in my version-control strategy over time. Now I break my branches into three categories:
- refactor
- feature
- bug
The former editor in me hates that I have a verb mixed with two nouns. 🤦♀️ However, the structure works well for me. I also only have one other engineer accessing my code (my daughter, Destinee) and my projects are pretty straightforward.
I’ve also gotten better about restricting the scope of my code modifications for a single branch. But there are still times I just can’t help myself from tinkering with my unrelated code (especially css) or forget to create a new branch while testing on my main branch. But, you know…

This structure creates a natural pause between writing code and deploying it—giving you time to review what the assistant actually generated. Git-based workflows also make it easier to roll back changes and pinpoint exactly what was introduced and when.
Some teams find it helpful to tag or label AI-generated changes (e.g., ai-draft, copilot, or generated-by) to route them through an extra review step or automatically block them from deploying without sign-off.
Ask the Model to Explain Itself
I’ve learned to treat AI suggestions like code from a brilliant but overconfident junior developer. To wit they often make assumptions that seem reasonable but don’t match your actual setup. So when I find something that seems off, like unfamiliar file paths or database operations, I’ll ask pointed questions: “What happens if that directory doesn’t exist?” or “Show me the exact SQL this generates.”
And if I spot a trend (like AI’s tendency to create new functions instead of fixing existing ones), I’ll add the instruction to my boilerplate instructions I include in every new project, e.g., “Please fix functions over creating new ones. Only create a function if there’s no current function that can be improved.”
I’m also an absolutely stickler on requiring AI tools to be generous in comments and—with rare exception—go line by line through the code to ensure it hasn’t run roughshod over code responsible for other functionality. If something doesn’t make sense, I have the comment to use as a jumping-off point for further discussion.
Organize Your Code
I’ve found that AI-generated code can be very chaotic. So I put bumpers in place to keep my code tightly organized. It’s a work in progress, but it has helped me corral updates across different tools, stages in development, and contributions from other developers.
I now break my code up into categories, subcategories, and occasionally tertiary categories. I use projects in ChatGPT and Claude and include my comment templates in the initial instructions when I create a new project:
Python
# ========================================================================
# Category
# ========================================================================
# ================================================
# Subcategory
# ================================================
# ===============================
# Tertiary subcategory
# ===============================
JavaScript/CSS
/* ======================================================================
Category
======================================================================= */
/* ================================================
Subcategory
================================================ */
/* ==============================
Tertiary category
============================== */
HTML
<!– ===================================================================
Category
=================================================================== –>
<!– ================================================
Subcategory
================================================ –>
<!– ==============================
Tertiary category
============================== –>
After experimenting with different comment styles for categories of code, I settled on this because I like how scannable it makes my code.
Capture Logs
If something does break, it’s much easier to diagnose if you can see the full chain of events: what the assistant was shown, what it replied with, and what was executed. This is where, to be fair, users share responsibility in these catastrophic failures. In my early days of code vibing, I relied too heavily on explaining errors to the AI tool using natural language and the logs from my terminal. Now I rely much more heavily on tail and curl commands in different terminals in VS Code. I will set them up early on by using the + button in the terminal (which is how you create multiple, parallel terminals) and let them run the entire time I’m coding.
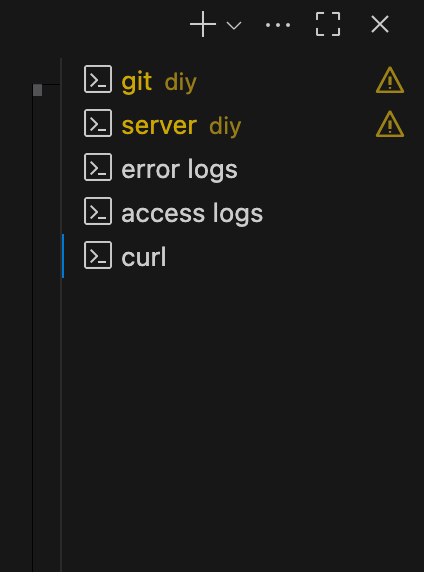
Here are the ones I use most frequently:
- Error logs: tail -f /[my app path]/[app-name]/logs/error.log
- Access logs: tail -f /[my app path]/[app-name]/logs/access.log
- Curl: curl -v http://localhost:8002/tools/ai-timeline/ | head -n 20
The tail commands basically say, “Watch the log files in my logs directory for my AI Timeline tool (for example) and stream new entries to the terminal in real-time.” I also highly recommend asking your AI tool to group all logs into a dedicated ‘logs’ directory. I’ve found its tendency is to litter the root directory with them, which I don’t like. 🧹
The key I learned was to keep them running in the background. When I was newer to app development and my vibe was kinda weak, I’d run them in my main terminal. But then I had to keep killing the server to run these commands (as well as update GitHub). Now I have dedicated terminals for each of these tasks. But feeding Claude these logs has dramatically reduced the number of passes bugs take to fix because Claude has a better view into the details. When I get an error, if I can’t confidently fix it myself, I’ll break my response up into sections, e.g., explanation of what I see in the browser, terminal logs, browser logs (if there’s a JavaScript error), error logs, access logs, and/or curl output.
I personally only run the curl command when I hit a 404 or 500 status code, but I’m sure there are more uses for it. I learned the hard way to restrict this output with the ‘head -n 20’ option, which just means “only show the first 20 lines.” Without it, curl can dump hundreds of lines of HTML into the terminal, which then pushes all other terminal logs out of view.
I also instruct Claude to use logs in my Python and JavaScript after one try. AI tools are notorious for being overly confident in their fixes, and I’ve wasted hours of my time implementing code that sent me deeper into a wormhole of bugs that my AI assistants concocted in some fever dream. (I share my go-to prompt instructions below.)
And for tracing prompts, tools like LangSmith and PromptLayer are fantastic at creating audit trails without much overhead.
Restrict permissions by default
If the assistant doesn’t need write access to production, staging, or sensitive services, there’s no need to give it that access. Think of it this way: Would you give your house keys to someone who just needs to mow your front lawn? The same principle applies to AI assistants. You can create separate API tokens with minimal permissions, e.g., let it read data, but not delete it.
For production databases, I never give AI tools direct access at all. Instead, I’ll export sample data or use a replica with fake records. Most cloud providers (AWS, GCP, Azure) let you create temporary ‘visitor passes’—credentials that expire after an hour or only work for specific operations. It’s like giving someone a key that only opens the garage, not the whole house.
GitHub’s fine-grained personal access tokens are another useful tool for limiting repo access to only what’s needed for testing.
Confirm, confirm, confirm
You almost can’t be too careful when coding with AI. Earlier this year I was traveling and had to export a database that was stored on my iMac and then import it to my new Macbook laptop. Since this was a production database, I was paranoid about data loss—so paranoid that I ran SELECT COUNT(*) queries before AND after just about every operation and created a backup before I did anything. Call it overkill, but I’ve seen too many “quick fixes” turn into data dumpster fires.
One red flag I’ve learned to watch for is suspiciously quiet code. If the model suggests operations that skip logging, return nothing but “Success!”, or don’t show you what they’re actually doing (as happened in the Gemini CLI incident), pump the brakes. The most dangerous code often runs silently. Now I treat every AI suggestion like a toddler. If it gets too quiet, I get suspicious.
My paranoia toolkit includes:
- ls -la: Before and after file operations (Did that file actually get created? Is it the right size?)
- cat [filename]: To print a file’s contents to the terminal. (You can add | head -20 to peek inside larger files without flooding your terminal.)
- SELECT COUNT(*) FROM table_name: My database safety blanket to make sure I didn’t lose records (aka rows).
- df -h: Check disk space to watch for issues like AI copying a 50GB database on a drive with 10GB free space
The few extra seconds these checks take have saved me hours of recovery time.
AI Tools Need to Do More Too
Amjad Masad, CEO of Replit, said in a post on X that they were working on fixes. Some he listed:
- Automatic dev/prod database separation: Replit is rolling out automatic separation between development and production databases to prevent agents from accidentally touching live data.
- Staging environments: They’re building dedicated staging environments to give users a safer space for testing AI-generated code.
- One-click project restore from backups: He said Replit already has backups, which users can restore their entire project state easily if the agent makes a mistake.
- Forced internal docs search: The agent didn’t reference Replit’s internal documentation properly, so they’re updating it to search official docs by default.
- Planning/chat-only mode: A non-destructive mode is in development that lets users brainstorm or plan with the agent without executing code.
I personally don’t envision ever giving AI agents write access to my production codebase or any of my databases. That’s just me. But for tools that sell that functionality, more needs to be done to protect users from catastrophic data loss.
Bonus: My Prompt Instructions
Below are my prompt instructions I use for every coding project I set up in Claude or ChatGPT. (I gave up on Gemini last year as it was the most frustrating tool for coding as it would list all the possible causes for an error instead of suggesting fixes. After many attempts at prompt engineering, I withdrew my credit card info and never looked back. #ymmv).
- Please never remove my comments or docstrings.
- Please follow this format for docstrings:
"""
Computes the similarity between two sets of weighted keywords using cosine similarity.
Args:
broken_weights (dict): Weighted keywords from the broken URL
candidate_weights (dict): Weighted keywords from a candidate (valid) URL
Returns:
float: A similarity score between 0 and 1
"""
- Please fix functions over creating new ones. Only create a function if there’s no current function that can be improved.
- Be generous in comments. I prefer them be above the line they accompany, with a linebreak before it, unless they’re for individual parameter settings. Then I like them to be vertically aligned for easy scanning. Also, please start comments with a capital letter with no end punctuation (e.g., # Combine all unique keywords from both broken and candidate URLs).
- If you need to make small tweaks to my code, please always tell me explicitly where to add the code, including the line it will follow. And don’t return the entire file or function unless it’s small; just return the code I need to change plus previous snippet for context.
- Please point out new code by adding ‘NEW: ‘ to the beginning of the comment so I don’t have to replace an entire function unnecessarily.
- I really hate inline css and javascript. Please always recommend code to add to external files.
- I prefer a VERY slow, methodical pace. If a fix doesn’t work on the FIRST TRY, suggest logs and don’t stop logging until the issue is fixed.
- When you’re kind it makes my day and helps me feel more confident. I really enjoy partnering with you when you feel like a friend and it feels less stressful.
I don’t know why I say ‘please’ so much. ☕️👌 But these prompts help me secure an experience that’s enjoyable (with Claude being the best at acting like an actual coding buddy) while returning code I can understand and control.
Leave a Reply