
AI terms like inference, training, and prediction often show up in articles and conversations, but it’s not always obvious what they mean—or how they differ. These terms describe different stages in the lifecycle of an AI model. For this post I’m going to take a single use case—summarizing customer service emails—to explain each of these terms.
Training: Teaching the Model from Scratch
Training is the long, compute-heavy phase where a model studies large collections of labeled data. In our example, thousands of customer emails paired with high-quality summaries. During this stage, the model’s internal weights are adjusted so it can capture common phrases, complaint patterns, and the structure of an effective summary. Essentially, the model is learning the relationship between raw input (the email) and the desired output (the summary).
Behind the scenes, a data scientist usually starts with a structured dataset—often a spreadsheet or a CSV—where each row includes two columns: one for the input (the original email) and another for the expected output (the summary). This format is great for reviewing and editing the data manually.
But to train the model, the data usually needs to be converted into a format the training framework can read, which is most commonly JSONL (short for JSON Lines). In a JSONL file, each line is its own mini JSON object, typically structured like this:
{"input": "Customer email goes here", "output": "Summary goes here"}
{"input": "Customer email goes here", "output": "Summary goes here"}
{"input": "Customer email goes here", "output": "Summary goes here"}You can see what JSONL looks like out in the wild in my post about fine-tuning an open model for $50. It took me a hot minute to get used to there being no comma separators between lines.
But I digress…
The important thing to understand is this process lays the foundation for everything the model will do later. Once training is complete, the model is no longer learning; it’s ready to apply what it knows.
A dataset is typically split before training begins. It’s first divided into two parts: a training set and a testing set. The training set is then further split into a training and validation set. During training, the model learns from the training data and checks its performance on the validation set to adjust its parameters. The testing set is kept entirely separate and only used at the end to evaluate how well the model performs on data it has never seen before.
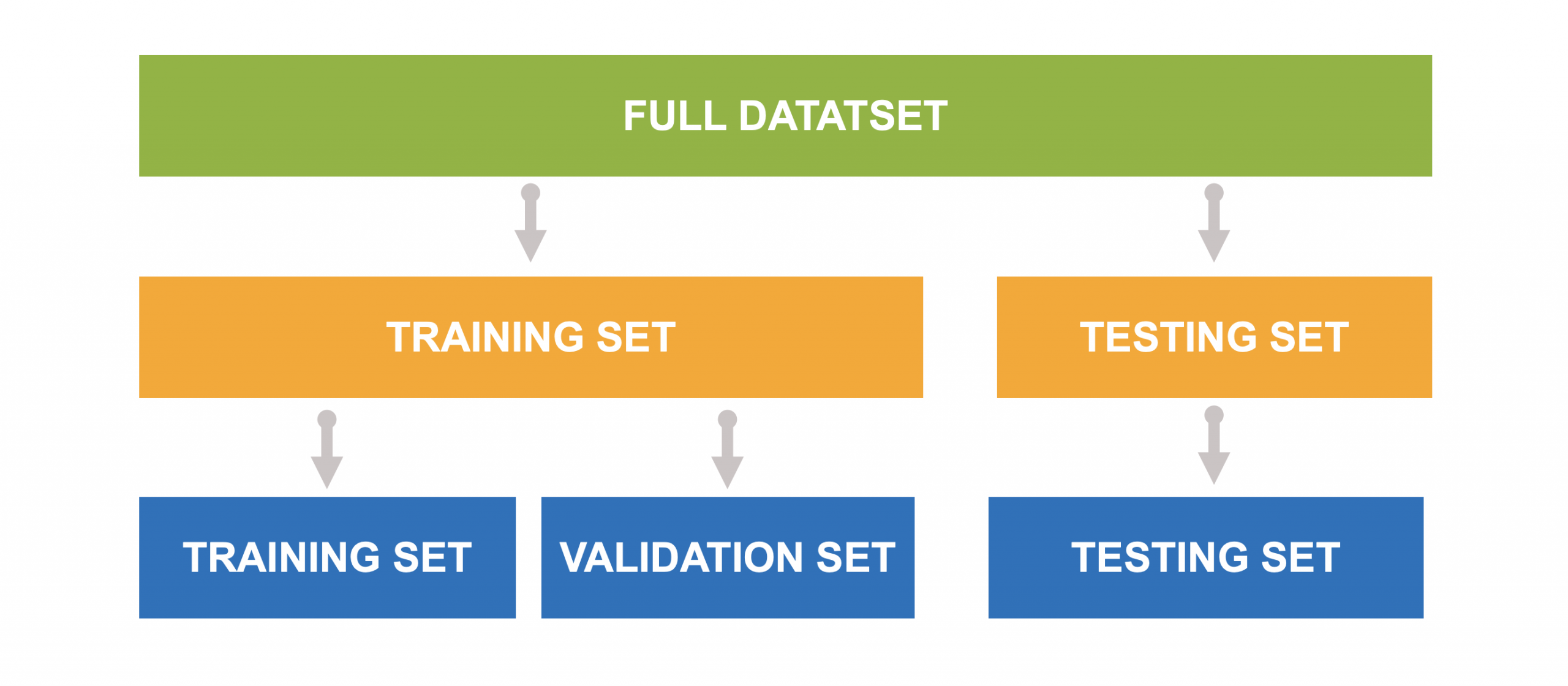
Engineers hold back this testing set to ensure the model generalizes well. ‘Generalizes well’ is another one of those terms you’ll eventually hear bandied about when talking about model training. It just means they want to see how well the model handles new, real-world data (in this case emails) it hasn’t seen before, rather than simply memorizing the training set. If the model performs well on this separate set, it’s a good sign that it will work reliably outside the lab. Once the results meet a target accuracy, the model cleared for real-world use.
Inference: Putting the Model to Work
Once a model is trained and validated, it’s ready to be used. That’s where inference comes in. Inference is the behind-the-scenes processing that happens every time someone gives the model a new input, like a fresh customer email. The model takes in the text, applies everything it learned during training, and generates a response. This all happens in a matter of milliseconds to seconds, depending on the model size and infrastructure.
In practical terms, inference is what powers AI tools in the real world. When a chatbot replies, a recommendation is served, or an email is summarized, inference is the engine doing the work in real time. It’s a one-to-one exchange. To wit, for every piece of input, the model produces an output.
Prediction: The Output of Inference
The prediction is what the model produces after inference is complete. It’s the finished summary that lands in the agent’s queue, or the answer a chatbot gives when you type a question. In our example, you send the model an email, it processes it (inference), and the result—a summary of that email—is the prediction.
Predictions can take many forms: a single sentence, a block of text, a label (like ‘urgent’ or ‘billing issue’), or even a number. What they all have in common is that they’re based entirely on what the model learned during training and how it applies that knowledge during inference.
Let me summarize the difference in terms anyone who’s managed a toddler can relate to.
Fine-Tuning: Teaching the Model Your Style
If the generic model sounds too formal—or too wordy—you can refine it with Low-Rank Adaptation (LoRA). LoRA keeps the original weights frozen and inserts small, trainable low-rank matrices alongside them. I explained in my post about prompt engineering vs fine-tuning that fine-tuning with LoRA is like remodeling your home vs gutting it and rebuilding it from the ground up.

A few hundred of your own email-summary pairs are enough to steer tone or length. These adapters can remain separate (saving memory at inference time) or be merged back into the base model later. LoRA costs only a fraction of full retraining, but still requires GPU hours proportional to model size and data volume.
Why This Matters
Understanding the difference between training, inference, prediction, and fine-tuning helps make sense of how AI actually works—and where the real costs show up. Most organizations don’t train models from scratch. They use pre-trained models, which means the model already knows how to perform general tasks like summarization, classification, or text generation out of the box.
But even with a pre-trained model, there are still decisions to make. If you want the model to better reflect your tone, structure the response in a particular way, or respond in a manner the base model wasn’t trained to respond (e.g., a homework app that works socratically like Khanmigo rather than spitting out the answer), prompt engineering or fine-tuning can help you customize it without retraining from scratch. But once a model is in use, every time it processes new input, it runs inference. And that’s where the ongoing costs come in.
Some teams access models through an API, where companies like Meta, Hugging Face, or OpenAI host the model and charge per request. Others choose to host models themselves. That can mean renting infrastructure from a cloud provider like AWS, Azure, or Google Cloud, where you pay for GPU time, storage, and networking. Or it can mean running the model locally on your own servers, which is something that requires upfront investment but may be more cost-effective over time for high-volume use cases.
Either way, inference is not free. Running a model at scale—whether it’s generating summaries, classifying content, or answering questions—comes with infrastructure and operational costs. Understanding these terms will hopefully help you decipher some of the data-ese your engineering and data science teams may speak.
Leave a Reply